Reconciling catalog data after import
Importing products or prices into NewStore is replication process. Usually there is a source system where products
or prices are stored and the next step is a safe transition of data into NewStore.
This task involves data replication with an exactly once guarantee and eventual consistency.
Exactly once is defined as product is imported into the NewStore platform once, not duplicated and data is not lost.
Eventual consistency is defined as the product imported is not updated immediately,
but in time it has to have values defined as in an import file.
However, some situations may result in incomplete import if there is an issue during the import process (e.g. wrong configuration, or incorrect data such as importing a product without a product id, or a pricebook without price). In such a case, you must compare all products and prices in NewStore with the original source of truth such as your product information management system (PIM)
This process is called reconciliation of data. Since product catalogs are typically large, reconciliation needs to be automated using API calls. This document explains what kind of issues can arise during the import, and how to use the Products Reconciliation API and the Prices Reconciliation API to reconcile data.
Do not scroll through the catalog via Get product by ID API calls to reconcile data.
Doing so is time consuming and resource heavy, as it transfers a large amount of data over the network from a rate-limited API.
This process also causes an artificial load on your NewStore system, apart from the regular usage of
Associate App, and can cause load-related issues downstream.
How do the reconciliation APIs work
NewStore provides the following APIs to make this reconciliation process cheap and scalable:
These APIs provide full snapshots of the products and pricebook for the last 24 hours. NewStore generates these snapshots every day for each tenant, for each catalog and pricebook. No separate configuration is needed.
NewStore runs this task every 24 hours and stores the output into plain .CSV files. When you call the above
reconciliation APIs, the CSV files are downloaded from the CDN. This prevents fetching the NewStore database,
and bombarding NewStore with millions of requests. A single API call downloads the whole
pricebook as a CSV file from the CDN (content delivery network), making the process cheap and scalable.
Data reconciliation scenarios
There are two scenarios for product reconciliation, identified by the symptoms:
- When some data from your external PIM does not show up in NewStore Associate App (e.g. a product doesn't have any price information, or you cannot scan a product because it is missing from the catalog).
- To recover from disaster when the product data in your external OMS is not complete compared to the data in your external PIM (e.g. in the external OMS some required fields are missing, such as line item color or size).
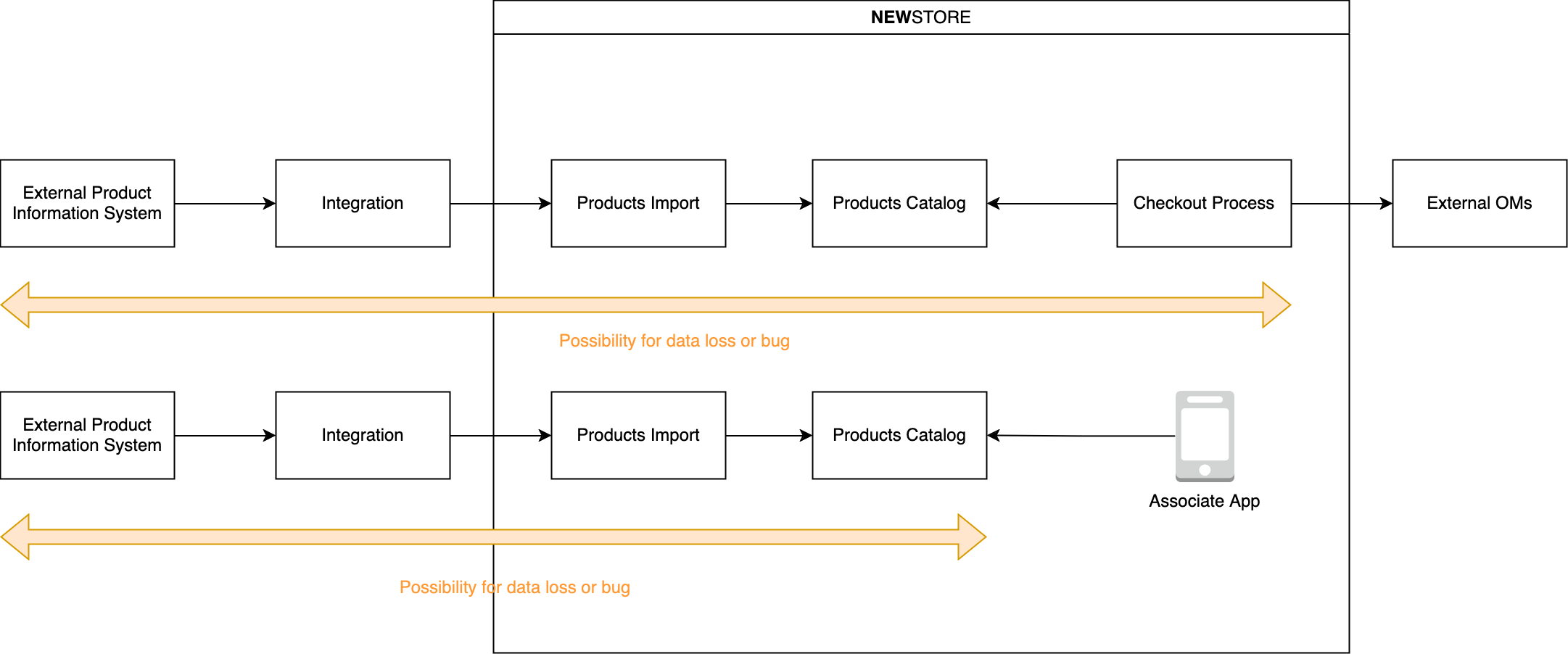
Example scenario 1 In this example scenario, an associate cannot see the product color or size in Associate App, and cannot scan the product because it is missing from the catalog or has the wrong price. An automated process needed to be built that can check all products imported into NewStore against the data in your external PIM regularly.
Example scenario 2 Products are available in an external product information management system. They need to be imported into NewStore via an integration and import system, and added to the catalog. These products are then fetched during the checkout process and product content is relayed to an external order management system (OMS) for each item. This usually do not happen and it is a disaster scenario when retailer requires a fix of malformed orders.
At any point in this route, there can be either unforeseen issues (e.g. incorrect products) or missing data. The outcome of such issues is that the final order in the OMS does not have all required fields, for example line item color or size is missing.
The following sections show you examples of how to deal with these situations.
Example: reconciling products with an external PIM
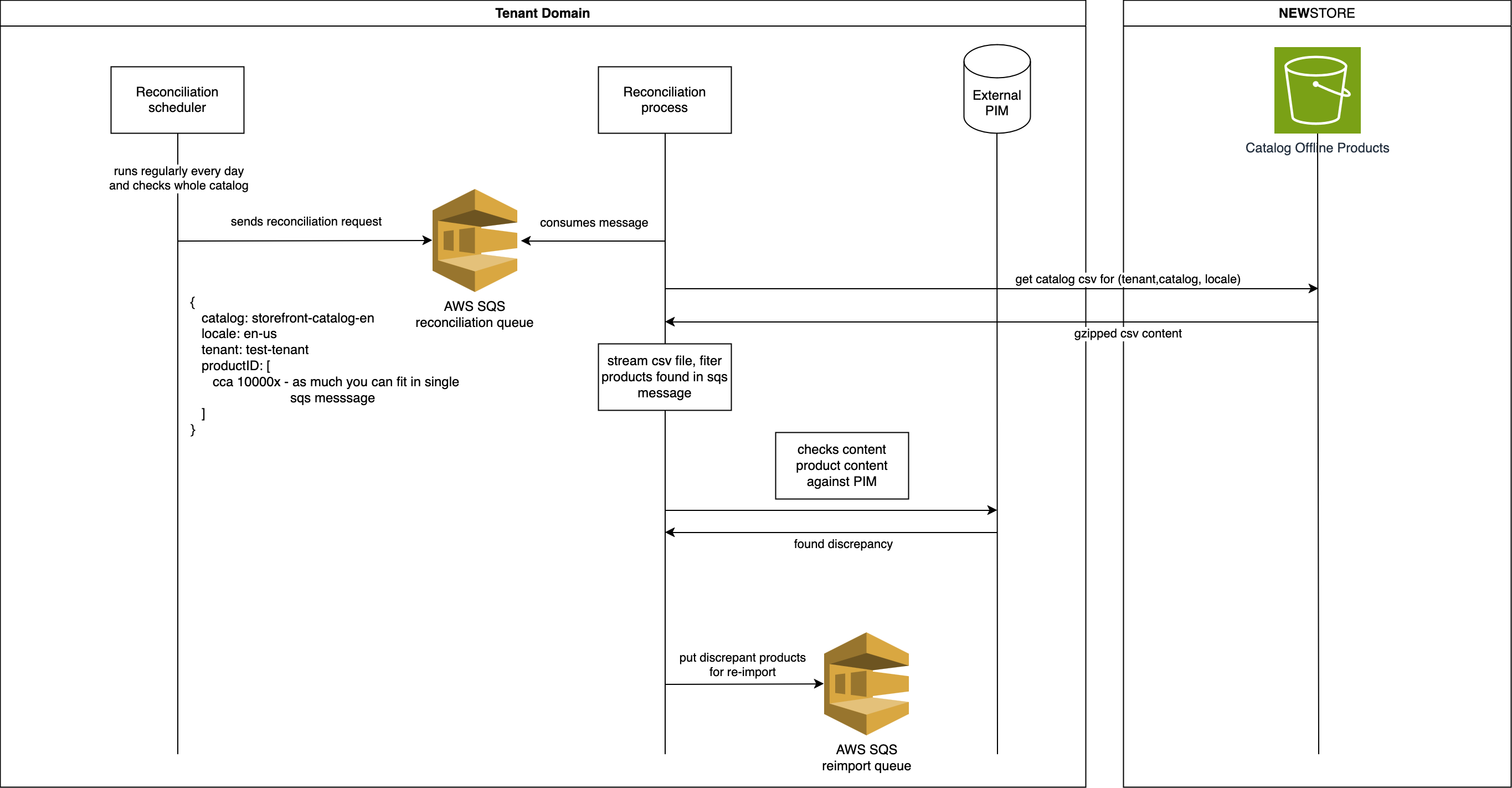
Prerequisites
The reconciliation process needs to be built by the retailer.
Process
In this example, we will look into a scenario where products are stored in an external PIM. Products are out of sync: product sizes and colors are missing.
To identify such products, the reconciliation scheduler runs every day and adds all products in PIM for inspection (or products imported in the last 24 hours). The scheduler creates SQS messages with batches of products to check.
Each message is processed by a reconciliation process and it can be run in parallel. This is an effective way to scale reconciliation based on your requirements.
For each message, the process downloads the offline catalog and streams it. This helps to avoid storing the CSV file locally, and reconciliation
can be completed in a single pass through the file.
Each line contains the product id and all fields imported into NewStore, which also includes the updated_at
value. Use the updated_at field value to filter and list products changed in the last 24 hours.
Then compare the product content with the data in PIM. Publish discrepancies to a separate SQS queue,
which can then be used for another inspection or a re-import.
After this solution is deployed, your integration can recover from data loss and identify discrepancies after the product reconciliation is completed.
Example: reconciling products with an external OMS
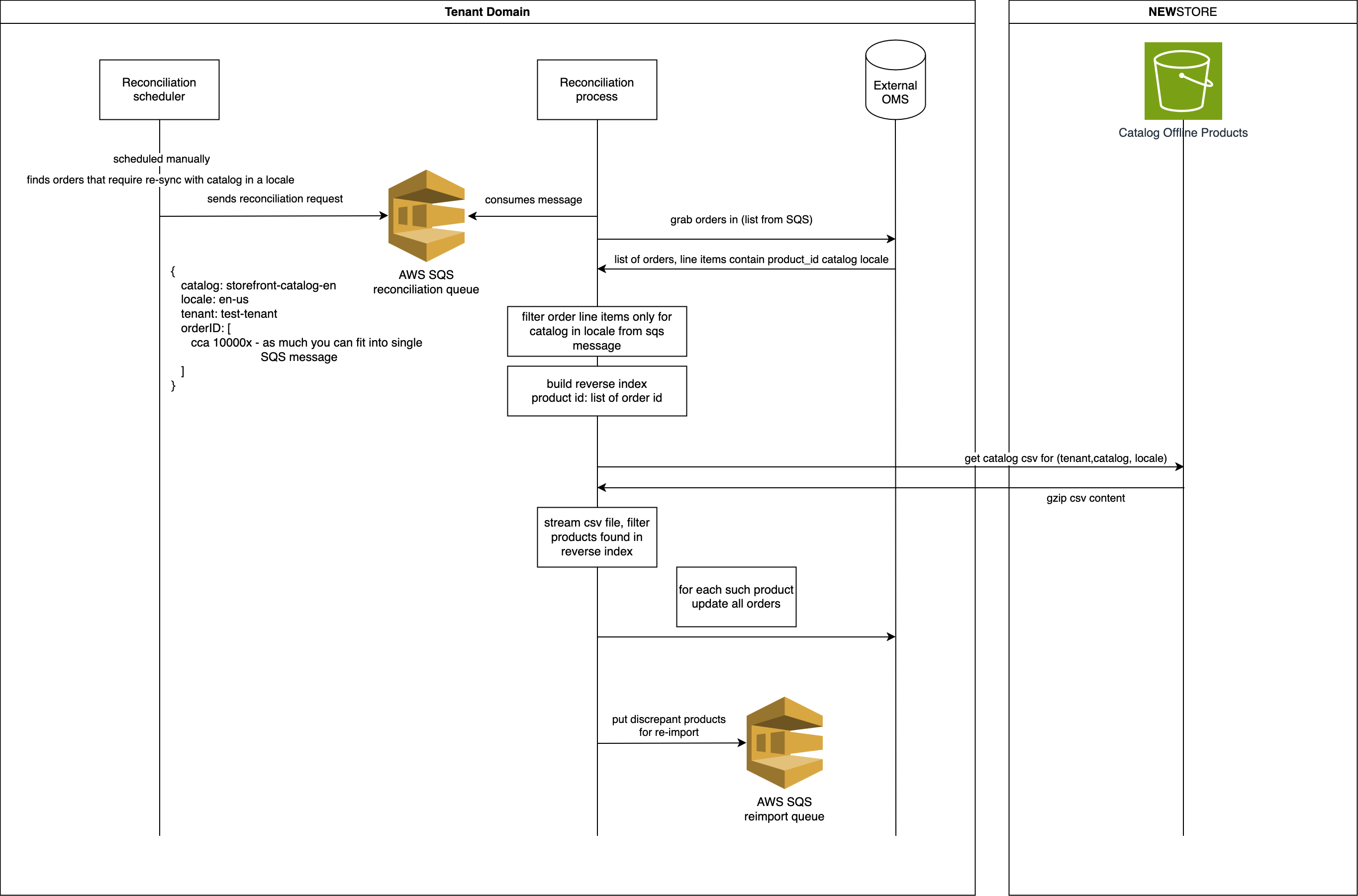
Prerequisites
The reconciliation process needs to be built by the retailer.
Process
In this example, we will look into a disaster recovery scenario where orders are not formed correctly in an external OMS and some orders are missing product sizes and colors.
Such orders need to be identified by an automated process called the reconciliation scheduler, which is run manually when retailer requires to recover malformed orders. Develop the reconciliation scheduler to find malformed orders. Then the scheduler checks whether all requested fields are filled (colors and sizes). Then it creates a list of problematic orders and group them by catalog and locale, chunks them by 10,000 orders. For each chunk, the scheduler will create a message in the SQS queue.
Each message can be processed by a reconciliation process that can run in parallel. This is an effective way to scale
reconciliation based on your requirements. You can run as many parallel tasks as the retailer's database can comfortably handle. For each process, create a
reverse index in memory. The index should be in a format like product_id[order ID1, order ID2, ...].
This structure makes the process efficient for the step that follows.
Download the whole CSV file, which can be gigabytes of data. For each line of the
CSV file, the process should check if there is a record in the reverse index.
Each line starts with the product id. Use it to find which orders needs to be updated.
Streaming helps to avoid storing the CSV file locally, and reconciliation
can be completed in a single pass through the file.
If colors and sizes are missing in the CSV file too, these products should be added for inspection in a separate SQS queue. The missing data points can be due to bugs or issues with the PIM. This list of erroneous products is a good starting point for another investigation or re-import.
After this solution is deployed, your integration can recover from data loss and identify discrepancies after product reconciliation is completed.